Why Pipelines?
If your experience with XML documents is limited to XHTML pages and SOAP-mediated RPC, the notion that one might want an XML Pipeline Language may seem a bit far fetched. What, you might ask, is your problem?
If your experience with XML documents is limited to XHTML pages and SOAP-mediated RPC, the notion that one might want an XML Pipeline Language may seem a bit far fetched. What, you might ask, is your problem?
In a nutshell, my problem is that my documents are rarely authored in exactly the format that they’re going to be used. That means that I need to perform some processing on them before they’re in their “final form.”
In the very simplest case, it’s just a straight transformation from XML to HTML (or PDF or what-have-you)

but the picture can quickly get more complicated. Using XInclude is perhaps the canonical example. Suppose that I’ve broken my document into different files. I might do this to make collaboration easier or simply for editorial convenience. I can (possibly) validate the individual files, but that won’t tell me the whole story. At the very least, it won’t let me check the actual structure of the whole document and it won’t allow me to check referential constraints such as ID/IDREF.
In order to process this multi-file document, I need to process the XInclude statements, then validate the result, then transform it:
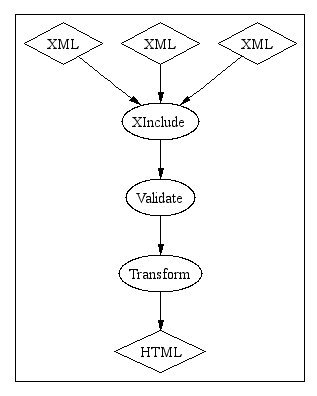
Here’s one last, real world example in a little more detail. Document reuse is one of the oft-cited benefits of XML and lots of people author to take advantage of it. Usually this means adding at least the occasional “profiling” attribute to a document. Large parts may be common to two systems, for example, but there are still places where system-specific text has to be added:
Consider the following paragraph about command line parameters to an XSLT processor. By setting the desired vendor condition appropriately, you can render it for either Saxon or Xalan:
<para xml:id="id8">You can pass stylesheet parameters to
&xslt; on the command line. The syntax is
<phrase vendor="saxonica">name=value</phrase>
<phrase vendor="apache">-PARAM name value</phrase>
where <replaceable>name</replaceable> is the name
of the parameter and <replaceable>value</replaceable>
is the string value you wish to establish as
its value.</para>Processing this document involves a two-stage transformation, first to build the “profiled” source file and then to build the result. Adding the names of the external files used in this process, our augmented XInclude and Profile pipeline looks like this:
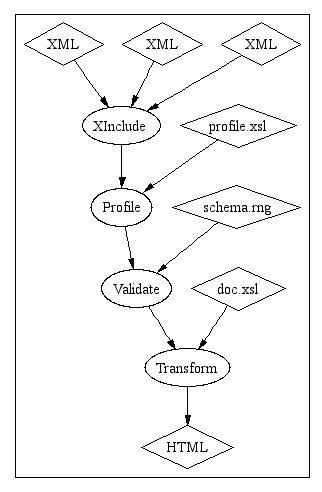
So building a finished document involves a series of stages. Authors typically attack this problem with shell scripts and source code management tools like make and ant.
That’s all well and good, but the reality is that these tools are overkill for the job (not that it isn’t possible to construct document processing scenarios where they aren’t) and they’re difficult for non-programmers to install and use.
All we really need here is a simple declarative language for composing pipelines. I’m not saying that this would reduce the learning curve for document processing applications to zero, but I do think it would make the curve less precipitous.
Take my word for it, the Makefile or
build.xml ant script
for the profiling scenario I described above would be a lot more
complicated than this:
<pipeline>
<stage process="XInclude"/>
<stage process="Transform" stylesheet="profile.xsl"/>
<stage process="Validate" schema="schema.rng"/>
<stage process="Transform" stylesheet="doc.xsl"/>
</pipeline>But that’s really all that’s needed.
I did some work in this area before; I helped edit an XML Pipeline Definition Language specification for the XML Processing Model Workshop. But in retrospect, useful as it was for the workshop, that language is too complicated for “version one” of a specification in this space. I think what I’ve outlined above is a lot closer to the 80/20 point.
Yes, some pipelines require conditional processing, loops, and complex dependency management, but a whole lot of them don’t. And getting something into the hands of beleaguered users that allows them to write a whole lotta simple piplines would be a good thing.
Having a standard way to do this would offer all the advantages that standardization usually brings: vendor support, interoperability, and eventually ubiquity to name just a few.
But since I’m not going to get that, I’m rolling my own.
Share and enjoy!