Building a Web Analytics Tool with MarkLogic Server V4.2
A few weeks ago, at the most recent New York MarkLogic User Group meeting, I demonstrated how to build a web analytics tool in about ten minutes using Information Studio and Application Builder in MarkLogic Server V4.2. Here's a summary, but you'll have to provide your own pizza and beer, I'm afraid.
When I was asked to speak at NYMUG, I knew just what I wanted to demonstrate: loading content quickly and easily with our new Information Studio application and customizing a built application using the new extensibility framework.
(It was suggested subsequently that this might be a good topic for a screencast. I made several attempts. Deb’s observations about my best attempt were, uhm, let's just say “not flattering” and leave it at that. Words are better anyway.)
Long story short, the scenario I came up with was a web analytics application. Web server log files contain a lot of interesting information. Each line in the log file identifies the IP address of the client, the date and time of the request, the URI, the response code, and other details. Some of them are highlighted below:

In short, there's lots of useful information in there, if only we had some way to explore it.
If we had that data in MarkLogic, we could easily build an analytics application to explore it. So let's do that!
(At the NYMUG meeting, I converted the log files to XML using a Perl script that I had lying around. Obviously that's inconvenient and what you'd really like to do is load the text files directly into MarkLogic. I've got that working now.)
We need to get these documents into MarkLogic Server. There are a lot of ways to do that, but by far the easiest way in MarkLogic Server version 4.2 is to use Information Studio.
Information Studio is available from the Application Services page which is usually on port 8002.

The Application Services page makes it easy to get started. Here's how easy it is, starting completely from scratch. First, let's create a new database.

Now, because I'm impatient, let's load up some data. We do that by creating a "flow".

In Information Studio, a flow is a reusable pipeline that loads data.

A flow consists of three parts: a collector, a set of transformations, and a target database. The collectors and transformations are "pluggable", you can write your own and they become part of the Information Studio UI automatically.
Information Studio ships with two collectors, a browser drop-box and a filesystem directory collector. The browser drop box let's you drag-and-drop files into the database. The filesystem directory collector reads documents from the filesystem. I've used the pluggable API to write a “log” collector that reads web log files and turns them into XML.
I simply choose it from the list of available collectors.

Then I configure it by pointing it to the log files. (Yeah, this page could use some CSS and a “Done” button; mea culpa.)

The ingestion settings are where I can configure things like the number of documents
in a single transaction, the filename filter, etc. For this demo, I've put the logs
in
files that end with “.txt” to distinguish them from other detritus
I've got hanging around in the tmp/logs directory.

The transformations section of the flow is where you specify things like renaming or deleting elements, normalizing date formats, validation, or running arbitrary XQuery or XSLT code. At the NYMUG meeting, I used a transformation step to normalize the format of dates, but I don't need to do that now because my collector stores them in the right format directly.
When I click “Start Loading”, Information Studio begins loading the files. This takes place in the background and uses as many transactions as required, so you can load an arbitrary amount of data. You can navigate away from the status page without interrupting the process.

After some time, the data is loaded.

If there had been any errors, there would be links to them here. We can peek at the resulting data in CQ.

Now I'm ready to configure some indexes. I can do that from the Application Services page by selecting the database and clicking “Configure”.

The database settings page lets me choose some common configuration options, often avoiding a trip off to the full complexity of the administration UI.

I want to add range indexes for some elements.

The domain is a string index. Note that I can just type
part of the name and Information Studio will find matching elements for me.

The datetime is an xs:dateTime index:

And so on. I want six indexes: domain, datetime, method, uri, status, and user agent.

Now that I've created the database, loaded some data, and setup some indexes,
it's time to go off to Application Builder to create the application. This will
be the LogExplorer application operating on the
LogExplorer database:

Application builder makes it really easy to construct a search application with faceted navigation and full text search. You setup the application by answering questions on each of its six tabs.
The first tab is for appearance. I've changed the titles, but you can configure CSS and other aspects of the appearance here too.

The search settings are where faceted navigation is configured. The facets are driven by range indexes, which is why I created them first. Based on those indexes, Application Builder has created a very reasonable set of defaults.

I'm just going to configure the
domain constraint to allow more items per facet:

And the
uri facet to allow even more:

Those are the two of the most interesting facets for this application. The defaults on the sorting tab are fine.

The results tab is where we can configure how search results will appear.

This is a pretty narrow, data-focused application. There's not a whole lot to display, really. In an application where the data included more prose content, this would be more interesting.
That said, I'm going to remove all the snippet fields, there's nothing to sensibly snippet on in our data:

And I'm going to configure the title and metadata sections a little bit.

After search results, the content tab is where you can configure how an individual search result will appear.

Like the search results, there's not a lot that we can usefully do in the UI with this data. We'll come back later and use our own custom XSLT to make this better. In the meantime, we can clean it up just a little bit:

The last tab is for deployment.

Pushing the deploy button will actually start the process of creating a modules database and generating code to reflect the choices we've made in Application Builder.

After a few moments, our application pops up, ready to use:

Out of the box, we get faceted navigation
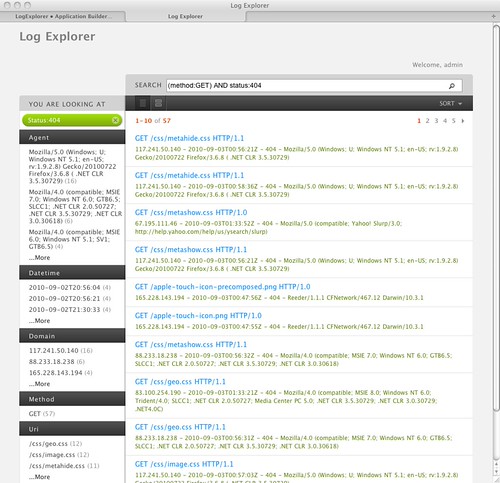
and full-text search, and any combination of them that we'd like.

(Ok, here's where a screencast might be nice. We could click around and watch all the results filter through.)
If you click on any individual search result, you get the details view:

At this point, we've created a useful analytics application for server log data in about ten minutes without writing a single line of code (my log collector excepted, but I expect there'll be a lot of pluggable collectors available soon, so I don't think it's unreasonable to imagine that you could get one you wanted without writing any code).
Let's move on to some customizations. One of the really irritating things about Application Builder in MarkLogic Server V4.1 was the fact that most customizations of a built application interfered with your ability to redeploy the app. In other words, once you left the comfort of the AppBuilder UI, you could never return.
Fixing that was the first real task that I undertook when I joined the Application Services team. Let's create a WebDAV server for the modules database and see what's in there.

As before, the bulk of the generated code is in /application/lib.
What's new is the custom folder that contains code you can use
to override the defaults provided in /application/lib.
Application Builder creates the custom folder when it generates
the initial modules database, but it will never overwrite the files
in there on subsequent redeployment. So your changes are safe!
If you open up
appfunctions.xqy, you'll see that it's a mostly
verbatim copy of
/application/lib/standard.xqy, except that each
function is commented out.

The first customization that I want to show is adding geospatial
data to the domain names. In general, it's not difficult to figure out
what to modify, the application page is built in a more-or-less straightfoward,
top-down manner. After a little inspection, I figure out that what I
want to do is change the browse-facets function.
I do this by uncommenting the version in appfunctions.xqy
and changing it to do what I want. In this case, if the domain facet is being shown,
I want to do a IP-address-to-geospatial-location lookup and add the results to the
facet name.

As long as we're in the neighborhood, let's replace
apptransform-detail.xsl with a stylesheet that
does something more attractive with the log entries.

Now if we go back to the main page and reload, we'll see that there's a geospatial location associated with many IP addresses. (In general, the mapping from IP addresses to geographic locations is a bit rough and approximate, but “US, Lisle, IL” is still more interesting than “67.195.111.46”, even if it's not exactly right.)

And if we go back to the details page, we'll see that that's prettier too.

Because we made these changes in the custom folder, we could
go back to Application Builder, make changes in the UI, and redploy our application
without
losing (or breaking!) any of our customizations.
Now, it's all well and good to build a high-performance search application with 800 or so log entries. But what about real scale? No one at NYMUG wanted to sit around and wait while I loaded tens of thousands of log file entries, least of all me.
In the best tradition of television cooking shows, I came prepared with a database that I constructed earlier. By simply going to the admin UI and changing a few parameters, I was able to relaunch the application on a database of more than ¾ million entries.

I also took the liberty of making a few more improvements:
-
I changed the datatime facet to be bucketed by day,
-
I added a hits/hour chart to the home page,
-
and I plugged a Google map into domain facet results.
The resulting home page shows the bucketed dates and the chart.

And a domain facet constraint now includes a map.

None of these improvements took more than a few
minutes to implement, although I didn't actually do them “live” at the meeting.
I figured I was tempting the demo $DIETY plenty, thankyouverymuch.
I did cheat in one small way. In order to make the geospatial queries perform at scale, I added the latitude and longitude to each entry, rather than looking them up “on the fly” as I did in the example I showed earlier.
Of course, I could make that part of my custom collector too, so it would just happen automatically.
In any event, the combination of Information Studio to load data and Application Builder to create search applications puts some incredibly powerful tools within the reach of a few mouse clicks.
Comments
This is very very cool, as usual. I have one question. How would you configure it to dynamically load the log files? Would it be possible to have new data piped into the server in more-or-less real time, so that I could hit a page, and see the resultant log entry in the server without too much latency?
That's an interesting question. If you got more-or-less real time access ot the tail of the server log, there'd be no trouble sending it to MarkLogic.
Maybe if you wrote a little cron job or other script that could extract the tail of the log every few seconds?
For ingestion, I'd probably set up a simple REST endpoint on the server that you could POST the lines to, instead of making it explicitly an Information Studio flow.
All in all, entirely doable and the analytics should update as fast as you pour in new entries.
Norman, would you please elaborate on how one could trigger loading of new data into MarkLogic? In particular, can you point me to the ML document that explains how to "set up a simple REST endpoint on the server that you could POST the lines to." Thanks very much. Sol
Here's a quick example off the top of my head.
xquery version "1.0-ml"; let $media-type := if (contains(xdmp:get-request-header("Content-Type"), ";")) then normalize-space(substring-before(xdmp:get-request-header("Content-Type"), ";")) else xdmp:get-request-header("Content-Type") let $format := if ($media-type = "application/xml" or $media-type = "text/xml" or ends-with($media-type,"+xml")) then "xml" else if (starts-with($media-type, "text/")) then "text" else "binary" let $post-body := xdmp:get-request-body($format) return <posted content-type="{$media-type}" format="{$format}"> { if ($format = "binary") then xs:hexBinary($post-body) else $post-body } </posted>Thank you for the example. And, please pardon my ignorance. I'm very new to MarkLogic but the example looks like something that runs in CQ. How do I get data into MarkLogic on demand? I'm working on a search application that lets the user mark results from the search and then the marked results get inserted into MarkLogic. I'd prefer to do this on demand rather than with a cron job. Thanks. Sol
Setup an HTTP application server. For the purposes of illustration, let's say it's running on port 8100 on a machine called "devbox". Store the XQuery above in a file called "post.xqy" and put it in the modules directory of that application server.
Now you can use any client tool you like to issue HTTP POST requests to
http://devbox:8100/post.xqy. That will cause the XQuery to run and return thepostedelement. That's not very useful, so change the code to doxdmp:document-insertor whatever is appropriate. You may also want to pass additional URI parameters; you can get at those withxdmp:get-request-field.I hope that helps. If you'd like to talk in a little more detail about your application, feel free to drop me a note in email.
Yes, your comments are very helpful. I think I get the gist of what you're saying. Let me play with your example in an app server and see if I can get this all to work. Thanks very much for your help. Sol
I ended up creating a simple xquery script to import records on demand. It expects a "uris" http header variable containing one or more space-delimited uris, it splits them with tokenize, and then loads them with a for loop and xdmp:document-load. I set the app's authentication to be basic and then I tested the whole thing with:
curl --header "uris: uri1 uri2 uri3" -u user:password appHost:port/import.xqy
I would post the code but your comment system keeps stripping out the XML tags even when I wrap the whole thing in a < code > tag.
Thanks very much for your help.
What you describe is certainly an option. If you escape the markup, you should be able to post code.